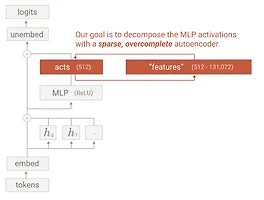
 [논문] Towards Monosemanticity: Decomposing Language Models with Dictionary Learning
https://transformer-circuits.pub/2023/monosemantic-features/index.html Towards Monosemanticity: Decomposing Language Models With Dictionary LearningAuthors Trenton Bricken*, Adly Templeton*, Joshua Batson*, Brian Chen*, Adam Jermyn*, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, A..
[논문] Towards Monosemanticity: Decomposing Language Models with Dictionary Learning
https://transformer-circuits.pub/2023/monosemantic-features/index.html Towards Monosemanticity: Decomposing Language Models With Dictionary LearningAuthors Trenton Bricken*, Adly Templeton*, Joshua Batson*, Brian Chen*, Adam Jermyn*, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, A..






