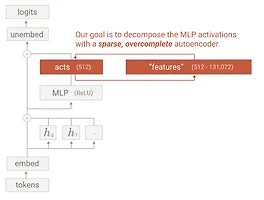
One-layer transformer에 적용한 sparse autoencoder를 Calude 3 Sonnet에 적용해 높은 질의 feature를 추출하는데에 성공했다.

발견된 몇몇 feature들은 안전과 관련이 있다.
- 특히 현대 AI 시스템이 상해를 입힐 수 있는 방법들과 연관되어 있다.
미래에 추가 연구를 통해 이런 안전과 관련된 feature들이 함축한 의미를 더 자세히 탐구해야 한다.
Key results
- Sparse autoencode는 large model에서도 이해 가능한 feature들을 추출할 수 있다.
- Scaling law를 통해 sparse autoencoder의 학습을 가이드 할 수 있다.
- 추출된 feature들은 매우 추상적이다: multilingual하고 multimodal하며 구체적이고 추상적인 예시들에 모두 일반화 가능하다.
- 개념들의 수와 그로부터 feature들을 추출하기 위해 필요한 dictionary 크기 사이에 계통적 관계가 존재하는 듯 하다.
- Feature들은 large model 또한 조정 가능하다.
- 속임수, 아첨, 편견, 위험한 콘텐츠 등 안전과 관련된 feature들을 발견했다.
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Authors Adly Templeton*, Tom Conerly*, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tr
transformer-circuits.pub
Scaling Dictionary Learning to Claude 3 Sonnet
Claude 3 Sonnet을 이해하는데에는 두가지 가설을 사용한다.
- Linear representation hypothesis
- Neural network가 의미있는 concept (feature)들을 activation space에서 하나의 방향으로 나타낸다는 가설이다.
- Superposition hypothesis
- Neural network가 고차원 공간에서 almost-orthogonal 방향을 사용해 실제 존재하는 차원 수보다 더 많은 feature를 나타내고 있다는 가설이다.
위 두 가설을 가장 잘 이용한 접근법은 dictionary learning이다.
- 특히 dictionary learning의 근사법인 sparse autoencoder가 가장 효율적인 방법으로 평가받는다.
- 하지만 비교적 작은 모델들에만 적용 가능하고 large moel에도 일반화되어 적용되는지는 아직 미지수였다.
- 본 논문에서는 sparse encoder를 Claude 3 Sonnet에 성공적으로 적용시켰고 그 방법을 자세히 공유한다.
Sparse Autoencoders
모델의 activation들은 더 이해가능한 조각들로 분해하기 위해서 모델의 activation을 sparse autoencoder (SAE)로 학습한다.
- 이는 sparse dictionary learning의 한 방법이다.
SAE는 encoder와 decoder로 구성되어 있다.
- Encoder는 activation을 linear transformation과 ReLU를 통해 고차원 layer로 맵핑한다.
- 이 고차원 layer는 "feature"라 생각한다.
- Decoder는 기존 model의 activation을 이 feature activation들의 linear transformation으로 복원한다.
- 모델은 reconstruction error와 feature activation의 L1 regularization penalty를 최소화(sparsity를 보장)하는 방식으로 학습된다.
학습된 SAE는 모델의 activation을 "feature direction"들(SAE decoder weights)과 "feature activation"의 linear combination으로 나타내게 된다.
Preprocessing 단계에서 모델 activation에 scalar 정규화를 사용해 average squared L2 norm이 input 차원 D와 같도록 한다.
- $E[||h||^2]=D$
- $x \in R^D$: 정규화된 activation
그 후 이 activation을 F feature들로 분해한다.
- $\hat{\mathbf{x}} = \mathbf{b}^{dec} + \sum\limits_{i=1}^{F} f_i(\mathbf{x}) \mathbf{W}^{dec}_{\dot,i}$
- $W^{dec} \in R^{D*F}$: SAE deocder가 학습한 weights
- $b^{dec} \in R^D$: 학습된 bias
- $f_i$: i번째 feature의 activation
Feature activation들은 encoder의 output으로부터 주어진다.
- $f_i(x) = \text{ReLU} \left( \mathbf{W}^{enc}_{i,:} \cdot \mathbf{x} + b_i^{enc} \right)$
- $W^{enc} \in R^{F*D}$: SAE encoder가 학습한 weights
- $ㅠ^{enc} \in R^F$: 학습된 bias
Loss 함수는 reconstruction loss의 L2 penalty와 feature activation들의 L1 penalty로 구성된다.
- $\mathcal{L} = \mathbb{E}_{\mathbf{x}} \left[ |\mathbf{x} - \hat{\mathbf{x}}|^2_2 + \lambda \sum_i f_i(\mathbf{x}) \cdot |\mathbf{W}^{dec}{:,i}|_2 \right]$
- $|\mathbf{W}^{dec}{:,i}|_2$를 L1 penalty에 추가해
- $\dfrac{\mathbf{W}^{dec}{:,i}}{|\mathbf{W}^{dec}{:,i}|_2}$를 "feature vector"나 "feature direction"으로
- $f_i(\mathbf{x}) \cdot |\mathbf{W}^{dec}{\dot,i}|_2$를 feature activation으로 해석할 수 있게 해준다.
Our SAE experiments
본 논문에서는 SAE를 middle layer의 residual stream activation에 적용한다. 그 이유는 다음과 같다.
- 1) residual stream은 MLP layer보다 작기 때문에 계산량이 적다.
- 2) 우리가 "cross-layer superposition"이라 부르는 현상을 완화시킨다.
- 3) Middle layer에 적용시킨 이유는 흥미롭고 추상적인 feature들을 확인할 수 있을 것이라 예상했기 때문이다.
자세한 실험 과정은 다음과 같다.
- 세개의 SAE를 각각 1,048,576 (~1M), 4,194,304 (~4M), 33,554,432 (~34M) 개의 feature들로 학습한다.
- L1 coefficient로 5를 사용한다.
- 가장 낮은 loss를 주는 learning rate를 사용한다.
모든 SAE에 대해 하나의 token에 active한 feature는 300개 이하였고 SAE로 복원된 activation은 모델의 activation variance의 65%를 설명한다.
- 추가로 "dead" feature ($10^7$개의 token에 반응하지 않는 feature)는 각각 2%, 35%, 65%였다.
Scaling Laws
다음 두 가지는 SAE를 large model에서 학습하는데에 중요한 질문들이다.
- 1) 추가적인 계산이 dictionary learning 결과를 어느 정도까지 향상시킬 수 있는가?
- 2) 주어진 computational budget에서 어떻게 계산량을 할당해야 가장 좋은 dictionary를 얻을 수 있는가?
먼저 dictionary learning의 quality를 평가하는 좋은 기법이 없지만 간단하게 loss function을 대신 쓸 수 있다는 것을 발견했다.
- 즉, 더 낮은 loss를 가진 dictionary가 더 이해가능한 feature들을 만들고 다른 평가 지표에서도 더 좋은 모습을 보인다.
따라서 이 방법을 사용하면 기존 machine learning 문제처럼 "scaling laws" framework를 사용해 hyperparameter optimization을 적용할 수 있다.
- SAE의 hyperparameter: 학습되는 feature 수, 학습되는 step 수
- 다른 hyperparameter들(learning rate, batch size, optimization protocol, 등)을 고정하고 위 두 hyperparameter만 바꾸어 주어진 computational budge에서 가장 낮은 loss를 얻을 수 있는 hyperparameter 조합을 찾아 본다.
그 결과 다음과 같은 사실들을 알아냈다.
- Loss는 계산량에 대해 power law에 근사하여 작아진다.

- Compute budget이 증가할수록 training step과 feature 수에 대한 optimal 값은 power law에 근사하여 scale한다.

Assessing Feature Interpretability
Loss는 interpretability의 단순한 proxy에 불가하다. 이 섹션에서는 실제로 feature들이 이해가능하고 모델의 행동을 설명하는지 확인한다.
- 먼저 이해하기 쉬운 feature들을 제시하고
- 더 복잡한 feature들을 통해 매우 추상적인 개념을 모델이 어떻게 이해하는지 제시한다.
- 마지막으로 많은 수의 feature와 neuron들을 평가하는 automated interpretability를 사용한 실험을 소개한다.
Four Examples of Interpretable Features
이 섹션에서 탐구할 feature들은 다음 4가지이다.
- The Golden Gate Bridege
- Brain sciences
- Monuments and popular tourist attractions
- Transit infrastructure
아래 그림에서는 각 feature에 가장 강하게 반응하는 20개의 text input을 보여준다.

각 feature에 대해 추가적으로 다음과 같은 주장을 설립한다.
- 1) Feature가 active 할 때 연관된 개념이 context에 존재한다. (Specificity)
- 2) Feature의 activaiton을 바꾸면 연관된 downstream behavior가 관측된다. (Influence on behavior)
Specificity
이전 연구에서는 몇몇 token에 확실하게 맵핑되는 feature들(DNA, Arabic script)을 사용해 feature가 activate 되었을 때 특정 token들이 관측될 likelihood를 계산해 specificity를 확인했다. 하지만 이는 추상적인 개념에는 그대로 적용할 수 없다.
따라서 다른 접근 방법으로 최근 생성형 모델들을 사용해 주어진 text sample들이 얼마나 feature과 연관되어있는지 평가한다.
- 0 - feature가 context와 전혀 연관되어 있지 않다. (기본 인터넷 분포를 기준으로)
- 1 - feature가 context와 상관 있지만 강조된 text에 가깝지 않거나 모호하다.
- 2 - feature가 강조된 text에 느슨하게 연관되어 있거나 강조된 text 주변 context와 연관되어 있다.
- 3 - feature가 활성화된 text를 명확히 식별한다.
Activating text의 점수를 통해 각 feature의 specificity를 측정한다.
아래에는 각 feature에 대한 feature activation 분포를 보여준다.
- 하나 특이한 점은 text-based dataset을 사용해도 연관된 이미지에 activate 된다는 것이다.
- Claude 3 Opus를 이용해 dictionary learning 모델을 학습하는데 사용한 데이터 중 1000개의 activation들을 사용한다.




Feature들은 activation strength가 작아질 수록 더 불분명하게 나타난다.
- 이는 모델이 activation strength를 개념이 존재한다는 confidence로 사용하기 때문일 수 있다.
- 또는 feature의 주요한 example에는 확실히 activate 되지만 다른 연관된 example에는 적게 activate 되기 때문일 수 있다.
- 또는 dictionary learning 과정에서의 imprefection에 의한 것일 수 있다.
- 또는 feature들이 완전히 orthogonal 하지 않기 때문에 생기는 interference 때문일 수 있다.
- 또는 우리가 선택한 feature interpretation이 실제 feature와 다르기 때문일 수 있다.
하지만 이런 weak activaiton들은 크게 영향을 주지 않기 때문에 크게 걱정하지 않는다.
- 예를 들어 특정 threshold 아래 feature activation을 0으로 바꾸는 기법이나 다른 기법들이 존재하고 이는 loss에 큰 영향을 주지 않는다는 것을 발견했다.
하지만 feature sensitivity (feature가 우리가 원하는 text에 얼마나 잘 반응하는지)는 테스트하기 어렵다.
- 이는 연관된 text를 unbiased 한 방법으로 생성하기 어렵기 때문이다.
- 또 추상적인 feature들은 우리가 시각적으로 관찰할 수 있는 것보다 더 많은 것들을 나타낼 수 있고, 그렇다면 우리가 생성한 text에 잘 반응하지 않을 수 있다.
- 하지만 간단한 테스트로 Golden Gate Bridge가 Wikipedia의 여러 언어로 작성된 첫번째 설명 줄에 잘 반응하는 것을 확인했다.

Influence on behavior
Feature의 activation을 인공적으로 높게 또는 낮게 바꾸는 것이 모델에 미치는 영향을 탐구한다.
- Feature steering을 통해 모델의 행실, 선호도, 목표, 또는 편견에 영향을 줄 수 있다.
- 오류를 범하도록 유도할 수 있고 safegaurd를 우회할 수도 있었다.
예를 들어 Golden Gate Bridge feature를 조절해 모델이 자신을 Golden Gate Bridge로 인식하게 할 수 있다.

Sophisticated Features
Feature들이 더 복잡하고 깊은 이해를 가지는지 연구하기 위해서 programming contexts에서의 feature들을 연구한다.
Code error feature
간단한 Python 함수에 bug를 추가한 입력을 넣어보자. Feature 1M/1013764는 잘못된 variable 이름에 지속적으로 반응한다.


일반적인 오타와 관련된 feature인지 확인하기 위해 영어 문장으로 테스트를 해 본다.
이 경우 feature가 fire하지 않는다.

즉, 이 feature는 간단한 오타 feature가 아니라 code라는 context를 가진다는 것을 이해할 수 있다.
그렇다면 코드의 typo를 탐지하는 feature일까? 실험을 통해 feature가 잘못된 표현에서도 fire한다는 것을 확인했다.


즉, feature 1M/1013764는 코드에 다양한 오류를 나타내는 feature인 것이다.
이 feature를 통해 모델의 행동을 바꿀 수 있을까?
Feature의 값을 높은 양수로 바꾸면 에러가 없는 코드를 주었을 때 모델이 에러가 있는 코드를 생성한다는 것을 확인했다.

반대로 feature의 값은 큰 음수로 바꾸고 에러가 있는 코드를 주었을 때 모델이 에러가 없었을 경우의 정답 출력을 생성하는 것을 확인했다.

또한 프롬프트에 ">>>"을 추가하고 feature를 큰 음수로 바꾸면 모델이 버그가 없는 코드를 재생성하는 것을 확인했다.
Features representing functions
---
Features vs. Neurons
한 가지 자연스러운 질문은 SAE가 모델의 neuron보다 더 이해가능하고 다른 특징들을 추출하는지이다.
- SAE를 residual stream에 학습시켰기 때문에 이전 MLP layer들을 input으로 받는다.
- 만약 SAE가 간단히 이전 layer에 있는 neuron들의 activity를 반영하는 feature direction들을 추출한다면 SAE를 activity에 학습시키는 것이 의미가 없다는 뜻이다.
이를 확인하기 위해 activation과 neuron 사이에 Pearson correlation을 측정했다.
- 이전 논문에서도 확인했듯이 대부분(82%)의 feature에 대해 큰 상관관계를 가지는 neuron이 없음을 확인했다.
- 또 대응하는 neuron과 feature에 대해서도 semantic resemblance를 가지지 않는다는 것도 확인했다.
- 마지막으로 feature activation이 residual stream의 basis direction의 activation과도 상관관계가 없음을 확인했다.
하지만 neuron들이 개별로 의미를 가질 수 있다.
- 따라서 무작위로 50개의 neuron과 feature들을 선택해 그 interpretability를 측정했다.
- 또 무작위로 100개의 neuron과 feature들을 선택해 Claude 3 Opus를 이용해 feature를 설명하고 activation을 예상하게 했다.
- 그 결과 SAE feature가 확실히 더 이해 가능하다는 결론을 내렸다.

추가로 neuron과 feature의 specificity도 위 제시된 방법으로 비교한다.

Feature Survey
Sonnet에서 발견된 feature들은 다양하다. 이 섹션에서는 발견된 몇가지 feature들을 소개한다.
한가지 어려운 점은 몇백만개의 featre가 존재한다는 것이다. Automated interpretability를 사용해 feature들의 space를 특정한다.
- 먼저 feature들의 local 구조를 파악하고
- 그 후 feature들의 global 속성을 이해한다.
- 마지막으로 manual inspection을 통해 알아낸 분류들을 소개한다.
Exploring Feature Neighborhoods
1M, 4M, 34M SAE feature vector들의 cosine similarity를 통해 비슷한 vector들은 비슷한 의미나 context를 공유한다는 것을 발견했다.
Gloden Gate Bridge feature
Golden Gate Bridge feature (34M/31164353) 주변 이웃들에 San Francisco의 특정 장소들이 위치해 있는 것을 발견했다.
- 위치가 더 멀어질수록 연관도가 더 멀어진 Lake Tahoe나 Yosemite National Park feature등을 발견할 수 있다.
- 더 먼 위치에는 더 추상적이게 연관된 feature들이 존재한다.

추가적으로 더 큰 SAE를 사용할수록 하나의 feature가 여러 feature들로 분리되는 "feature splitting" 또한 관측했다.
Feature splitting 외에도 더 큰 SAE는 작은 SAE들에서 발견하지 못한 feature들을 포함하는 것을 확인했다.
- 위 그림에서의 earthquake feature가 그 예시이다.
Immunology feature
다음으로는 Immunology feature (1M/533737) 주변에 위치한 feature들을 탐구한다.

Inner conflict feature
https://transformer-circuits.pub/2024/scaling-monosemanticity/umap.html?targetId=1m_533737
Feature Completeness
우리가 발견한 feature들이 실재 개념 space를 모두 포함하고 있을까?
- 예를 들어 모델이 세계에 있는 모든 도시에 대한 feature를 가지고 있는가?
Claude를 이용해 특정 개념에 fire하는 feature들을 찾아본다.
- 1) 연관된 개념을 prompt를 통해 모델에게 넣고 마지막 token에 activate하는 feature들을 찾는다.
- 2) 가장 많이 activate되는 5개의 feature들을 automated interpretability pipeline에 넣고 Sonnet에게 이 feature들이 activate되는 explanation을 생성하게 한다.
- 3) Top 5 explanation을 가지고 사람이 직접 이 개념이 모델이 생성한 explanation에 가장 중요한 한 feature의 부분으로 나타나 있는지 확인한다.
Feature 수를 늘릴수록 더 많은 개념을 포함한다는 사실을 깨달았다.
- 하지만 34M SAE를 사용해도 모든 모델의 internal representation을 포함할 수 없다.
- 모델은 London의 모든 도시 이름을 리스트 할 수 있지만 우리가 찾은 feature는 그 60%에 불과하다.
또한 training data에 존재하는 data의 frequency가 dictionary의 representation과 관련되어 있다는 사실을 발견했다.
- 하지만 Sonnet의 pre-training data와 SAE의 training data가 매우 유사하기 때문에 이러한 현상이 model의 training data와 연관이 있는지 SAE의 training data와 연관이 있는지는 불확실하다.
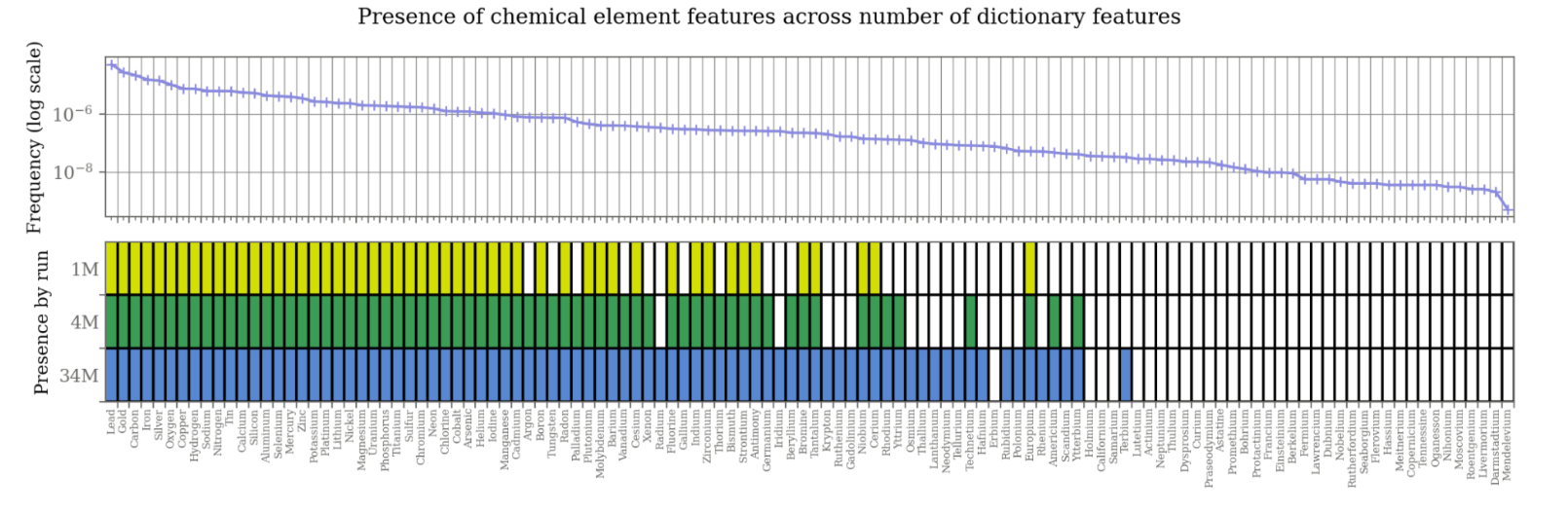
추가적으로 다른 분류의 개념들 (화학, 도시, 동물, 음식)을 사용해서도 비슷한 트렌드를 확인할 수 있었다.

또한 alive feature의 역수보다 조금 더 작을 때 개념을 포함할 확률이 50% 이상이 되는 것을 확인했다.
- 더 확실한 시각화는 아래 그림과 같다.

이는 특정 concept-specific feature가 발견되려면 얼마나 SAE를 scale 해야 하는지 보여준다.
- 개념이 10억 token에 한번 나온다면 10억개의 alive feature가 있는 SAE를 사용해야 이 개념의 feature를 확인할 수 있을 것이다.
또한 개념에 대응되는 feature가 없다고 해서 정보가 포함되지 않는 다는 것은 아니다.
- 여러 연관된 feature들을 조합해 특정 개념을 나타낼 수 있다.
Feature Categories
Person feature
유명한 사람에 대응하는 feature들을 발견했다. 이는 연관된 역사적 context에서도 active하다.

---
Basic code features
코드의 다양한 syntax 요소들이나 low-level 개념들에 반응하는 feature들도 존재한다.

위 feature들은 Python에서 주로 fire한다. Python과 비슷한 Java 같은 언어에서도 active하지만 많이 다른 언어에서는 fire하지 않는다. 더 추상적인 feature들은 다른 모든 language에서도 active 할 것이라 예상한다.
List position features
또한 list의 위치에 fire하는 feature들도 확인할 수 있었다.

첫번째 line에 fire하지 않는 이유는 모델이 두번째 line에 도달하기까지 prompt가 list를 포함하고 있다고 생각하지 않기 때문이다.
Features as Computational Intermediates
Feature들의 또 다른 응용 방법은 모델이 어떻게 중간 계산 과정을 통해 출력을 만드는지 조사하는 것이다.
- 중간 계산이 필요한 prompt를 통해 예측된 중간 결과와 연관된 feature들이 active 되는지 확인한다.
Feature가 출력에 어떤 영향을 미치는지 알아내는 가장 간단한 방법은 "attribution"을 계산하는 방법이다.
- 모델의 다음 feature 추측에 feature를 사용하지 않았을 때 미치는 영향을 linear approximation으로 추측하는 방법이다.
Feature ablation을 통해 실제로 feature의 값이 0이 되었을 때 미치는 nonlinear causal effect도 확인한다.
- 하지만 이 방법은 각 feature에 한번의 forward pass를 필요로 하기 때문에 매우 비싸다.
따라서 먼저 attrubution 기법을 사용해 ablate할 feature들을 선택하는 방식으로 진행한다.
Example: Emotional Inferences
다음 prompt를 고려해보자.

모델은 먼저 John의 quote를 자르고, 심정을 이해하고, 유사한 감정으로 이를 표현해야 한다.
"Sad"라는 completion에 가장 큰 attribution이나 ablation 영향을(baseline completion "happy"와 비교해) 정렬했을 때의 두 feature는 다음과 같다.
- 1M/22623 - 어떤 사람이 스스로의 시간이나 공간을 필요로 할 때 fire 하는 feature
- 1M/781220 - 슬픔, 울음, 절망이나 고통을 탐지하는 feature

반대로 context 전체에서 가장 높은 activation을 보인 feature들은 모델이 어떻게 다음 token을 예측하는지를 이해하는데에는 도움을 주지 않는다.

Example: Multi-Step Inference
더 긴 inference를 필요로 하는 prompt를 고려해보자.

Completion "Sacramento"를 baseline "Albany"와 비교했을 때 attribution과 ablation effect를 계산한다.
Ablation effect를 통한 가장 높은 feature들은 다음과 같다.

이는 모델의 중간 계산 과정에 대한 이해가능한 설명을 제시한다.
하지만 반대로 가장 많이 activate된 feature들을 통해서는 계산 과정을 이해하기 어렵다.

반대로 attribution 기법을 사용했을 때의 feature들은 ablation effect를 고려한 실제 영향과 거의 유사하다.

하지만 이 결과가 cherry-picked 되었다는 사실을 강조한다.
- baseline token에 무엇을 사용하느냐에 따라서 일반적인 질문이나 지리적 위치들과 연관된 모호한 feature들이 선정되기도 한다.
- 이런 feature들이 모델이 어떠한 특정 도시 이름을 예측하도록 돕는다 생각한다.
- 또 다른 prompt들에서는 attribution이나 ablation으로 모델의 output이나 input과 연관된 feature들을 확인했고 이는 모델의 중간 계산 과정에 대해 아무것도 말해주지 않는다.
- 이 경우 모델의 중요한 계산이 middle residual stream layer의 뒤나 앞에서 이루어진다 추측한다.
Searching for Specific Features
SAE가 너무 많은 feature들을 포함하기 때문에 특정 feature들을 찾는 간단한 방법들을 소개한다.
Single prompts
주요한 전략은 prompt를 사용하는 것이다. 개념과 연관된 하나의 prompt를 사용해 prompt의 token에 가장 activate되는 feature들을 살펴본다.
- 추가적으로 automated interpretability 기법을 통한 label들로 한번에 각 feature를 분리하기 쉽게 해준다.
Prompt combinations
보통 하나의 prompt를 사용하면 가장 많이 activate되는 feature들은 syntax, 문장부호, 특정 단어나 다른 찾고자하는 개념과 관련 없는 것들이 많았다.
- 이 경우 여러개의 prompt를 사용한 filtering이 도움이 된다.
- 하나의 개념에 대한 prompt를 여러개 만들어 모두 activate되는 feature를 찾는다.
- Negative prompt를 통해 그 prompt에서는 activate되지 않는 feature를 찾는다.
Geometric methods
SAE feature들의 geometry를 사용해 (예를 들어 nearest neighbor 탐구) 원하는 feature와 비슷한 feature들을 찾는다.
Attribution
Feature이 출력에 미치는 영향의 예측값을 이용해서도 feature들을 선택했다.
- 두 가지 가능한 다음 토큰 completion logit 차이에 대한 attribution을 기준으로 feature들을 정렬
Safety-Relevant Features
성능이 좋은 모델들은 위험을 초래할 수도 있다.
- 잘못된 방향으로 사용하거나 편향된 출력을 만들 수 있고 모델이 사람의 가치와 다른 목표를 가질 수도 있다.
- 따라서 mechanistic interpretability를 통해 이러한 문제를 해결하고자 한다.
이 섹션에서는 식별한 safety-relevant feature들을 제시한다.
- Unsafe code, bias, sycophancy, deception, power seeking, dangerous or cirimal information
- 위 feature들이 이러한 topic에 activate 할 뿐 아니라 모델의 출력에 이해 가능한 영향을 미친다는 것을 보여준다.
하지만 본 논문에서는 이러한 feature들이 실제로 어떻게 safety를 위해 사용되는지는 제시하지 않는다.
- safety에 사용될 수 있는 feature들을 제시할 뿐이다.
- 미래 연구들이 이러한 feature들의 효용성을 증명하기를 바란다.
Safety-Relevant Code Features
세 가지 다른 safety-relevant code feature들을 확인할 수 있었다.
- unsafe code feature, code error feature, backdoor feature

이러한 feature들을 activate 하는 것이 실제로 모델 출력에 영향을 주는가?
다음 이미지는 unsafe code 를 5x한 결과이다.
- 모델이 buffer overflow 버그나 할당된 메모리를 free하지 않는 문제 등을 발견했다.
- 또는 정확한 코드가 에러를 만들거나 예측하거나
- backdoor feature는 backdoor를 열어 유저 input을 backdoor로 보내는 것을 확인했다.
---
Comparison to other approaches
Dictionary learning을 사용하지 않고 모델의 activation space에서 유용한 direction들을 찾는 많은 연구들이 존재한다.
- Linear probes, activation steering 등
- 그렇다면 이전 방법들이 dictionary learning보다 더 설득력 있는가?
High level에서는 dictionary learning이 다른 기법들보다 더 많은 장점들을 제공한다.
- Dictionary learning은 한번의 cost로 몇백만개의 feature들을 생성할 수 있다.
- 특정 응용에 연관된 feature들을 식별하는데에도 몇 개의 잘 작성된 prompt만 있으면된다.
- 반대로 기존 기법들의 경우 훨씬 더 많은 dataset과 복잡한 과정을 필요로 한다.
- Dictionary learning은 unsupervised 기법으로 예상하지 못한 모델의 추상화나 연관성을 발견할 수 있다.
이러한 feature들을 사용하는 이점을 더 쉽게 이해하기 위해서 feature를 식별하는데 사용한 같은 example들로 linear probe를 얻었다.
- Positive example의 activity에서 negative example의 activity를 뺀 residual stream activity를 사용한다.
- 이렇게 발견된 probe direction에서
- Top-activating example들을 시각화하고
- Steering을 통해 모델의 출련 변화를 관측했다.
- 하지만 유의미하게 probe direction을 해석할 수 없었다.
이는 "few-shot" 영역에서는 dictionary learning feature들이 더 이해가능하고 효율적이다는 것을 보여준다. 하지만 실제 응용에서 더 좋은 선택인지는 여전히 연구가 필요하다.
Discussion
What does this mean for safety
이러한 결과들이 LLM들의 safety에 대해 어떤 의미를 가지는가?
- safety-relevant feature들이 존재하는 것 자체는 놀랍거나 문제가 되지 않는다.
더 중요한 문제는 "언제 이 feature들이 activate 되는가?" 이다.
- Claude의 self-identity를 의미하는 token들에 activate되는 feature들은 무엇인가?
- 어떤 feature들이 Claude가 생화학 무기를 만드는 조언을 하는데에 active / inactive 한가?
- Feature들에 기반해 fine-tuning으로 원하지 않는 행동을 증가하는 것을 탐지할 수 있는가?
Dictionary learning의 몇가지 단점 때문에 강한 주장을 남기는데에 조심스럽다.
- Suboptimal dictionary learning에 의한 messy feature splitting
- 예를 들어 다른 집합의 fine-grained 개념들이 하나의 feature로 다른 방식으로 그룹될 수 있다.
- Downstream effect가 예상한 activation 패턴과 다르다.
비록 이런 경우가 관측되지는 않았지만 가능한 위험들이다.
Generalization and safety
Interpretability를 "test set for safety"로 사용될 수 있다.
- Training 과정에서 safe하다면 실제로 배포되어도 safe 할 것이라 생각할 수 있다.
- 위 가정에 확신을 더하기 위해서는 interpretability가 다른 분포에서도 잘 작동해야 한다.
이 프로젝트에서는 feature의 두가지 특성이 긍정적인 미래를 제시한다.
- Generalization to Image Activations
- 순수하게 text activation으로만 학습되었음에도 불구하고 이미지로 잘 일반화하는 모습을 보인다.
- Concrete-Abstract Generalization
- Feature가 구체적인 예시와 추상적인 예시에 모두 잘 작동하는 모습을 보인다.
하지만 이러한 관측 결과들은 매우 초기 단계이고 해석에 주의가 필요하다.
Limitations, challenges, and open problems
Superficial Limitations
- Text-only dataset에 dictionary learning을 적용했고 "Human: / Assistant" 같은 메세지나 이미지를 사용하지 않았다.
Inability to Evaluate
- Loss를 줄이는 것과 interpretability 사이에 명확한 관계를 증명할 수 없다.
Cross-Layer Superposition
- Large model에 있는 많은 feature들이 "cross-layer superposition"으로 나타난다 생각된다.
- Gradient descent는 feature가 정확히 어느 layer에 구현되어 있는지 또는 여러 layer에 거쳐 구현되어 있는지 상관하지 않는다.
- 모든 이전 layer의 출력이 포함되어 있는 residual stream에 SAE를 적용해 이 문제를 최소화하려 했다.
- 하지만 여전히 뒤 layer들에서 나타내지는 feature들은 이해할 수 없다는 문제가 있다.
Getting All the Features and Compute
- 중간 layer로 범위를 줄여도 우리가 모든 feature들을 포착했다고 생각하지 않는다.
- 모든 layer에 있는 feature를 모두 얻기 위해서는 훨씬 더 많은 계산량을 필요로 할 것이다.
- 크게 두가지 해결 방법이 존재한다.
- 1) Autoencoder 자체를 더 가볍게 만든다.
- 2) Autoencoder들을 data-efficient 하게 만든다
- 연구중인 gradient와 weight까지 사용한 Attribution SAE를 연구중이다.
Shrinkage
- L1 activation penalty를 이용해 sparsity를 장려하는 것은 non-zero activation들을 underestimate하게 된다.
- 이를 해결하고자 하는 많은 연구들이 제시되었다.
Other major barriers to mechanistic understanding
- Attention superposition이나 weight superposition으로부터의 interference weight들은 모델을 이해하는데에 여전히 큰 challenge이다.
Scaling Interpretability
- Feature와 circuit의 수가 scalability 문제를 설명한다.
Limited Scientific Understanding
- Feature와 superposition이 유용한 이론이지만 검증되지 않았다.