
[논문] Knowledge Tracing: A Survey (2023)
https://dl.acm.org/doi/full/10.1145/3569576
온라인 학습 플랫폼이 보편화되면서 선생뿐만 아닌 기계가 학생들의 지식을 추적하고 학습 경험을 조정할 필요가 생겼습니다. 이는 Knowledge Tracing (KT) 문제로 정의됩니다. 본 논문에서는 KT 기법의 포괄적인 조사 결과를 보여줍니다. 특히 초기 KT 기법들부터 deep learning을 사용하는 state-of-the-art 기법들을 소개하고 각 모델의 이론적 배경과 benchmark 데이터셋의 특징들을 강조합니다. 또 연관된 기법들의 주요한 구현 차이점을 요약합니다. 마지막으로 현재 KT 기법들의 연구 공백과 가능한 미래 연구 방향을 제시합니다.
본 포스트에는 논문의 모든 내용이 포함되어 있지 않습니다.
1 Introduction
Knowledge Tracing 문제란
- 학생의 학습 정도를 학생과 교육 자료의 상호작용으로부터 알아내는 것
- 학생의 지식 주순을 나타내고 정의하는 것이 목표

위 그림은 한 학생이 문제 $ \{q_1, q_2, q_3, q_4\} $를 푸는 과정을 나타낸다.
Intelligent Tutoring Systems (ITSs)는 학생의 상호작용에 따라 스킬 $ \{k_1, k_2, k_3, k_4 \} $에 대한 지식 수준을 예측하게 된다.
문제점 및 고려사항:
- 각 문제를 푸는데 하나 이상의 skill이 필요할 수 있음
- 위 그림에서 $q_2$를 푸는데에 스킬 $ k_1 $과 $k_3$이 모두 필요
- 각 skill 간 의존도는 KT 기법에서 중요한 요소
- 위 그림 Dependency Graph에서 $ k_1$와 $k_4$는 $k_2$를 얻기 위한 선행 조건
- 각 skill에 대한 학생의 망각은 지식 소멸로 이어짐
- 위 그림에서 $k_1$은 가장 잘 기억되는 반면 $k_2$는 가장 쉽게 잊혀짐
초기 모델
- Bayesian inference approach
기계 학습 기반 모델
- Factor analysis에 기반
- 학생 관련 요소: 사전 학생 지식, 학습 속도
- 문제 관련 요소: 문제 친밀도, 이전 문제 풀이 수
- 학습 환경 관련 요소
Deep learning 기반 모델
- Deep Knowledge Tracing (DKT)
- 여러 관점에서의 deep learning KT 모델 연구 개발됨:
- Memory structures: Memory-augmented neural network에서 영감
- Attention mechanisms: Transformer 구조에서 영감
- Graph representation learning: 그래프 학습 기술에서 영감
- Textual features: 문제의 text를 활용해 필요한 스킬, 난이도, 관계 등을 포착
- Forgetting features: 학생의 망각을 고려
1.1 Contributions
본 논문은 전통적인 기계학습 관점부터 최신 deep learning 관점의 KT 기법들을 비교하고 요약한다
- KT의 주요 category 기법들을 비교
- 모델 디자인, 지식 수준 표현 방법, 문제와 스킬간 관계에 사용된 가정, 학생 망각 요소 등
- 각 category의 KT 기법들의 순차적인 발전 과정 요약
- 널리 사용되는 KT 데이터셋 특징 요약 및 주요 KT 기법들 성능 비교
- 아직 연구되지 않은 KT 응용 분야 제시
1.2 Survey Methodology
---
1.3 Scope and Structue
---
2 Categorization of Knowledge Tracing Models
2.1 Traditional Knowledge Tracing Models
---
2.2 Deep Learning Knowledge Tracing Models
2.2.1 Sequence Modeling for Knowledge Tracing
Terms
- 모든 문제 셋: $ Q = \{q_1, \ldots, q_{|Q|}\} $
- 상호작용 sequence: $ X = \langle x_1, x_2, \ldots, x_{t-1} \rangle $
- i 번째 상호작용: $ x_i = (q_i, y_i) $
- i 번째 문제 정오답: $ y_i \in \{0, 1\} $
정의
- 상호작용 X가 주어졌을 때 KT는 time step t의 새로운 문제인 $q_t$를 학생이 맞출 확률 $ p_t = P(y_t = 1 \mid q_t, X) $를 예측한다
모델
- Deep Knowledge Tracing (DKT)가 이 분야에 첫 모델
- Recurrent Neural Network (RNN)과 Long Short Term Memory (LSTM)을 사용
- 한계점
- 학생의 지식 수준 $h_t$에서 하나의 스킬만 고려
- 여러 스킬들 사이에 관계를 고려하지 않음
- 모든 문제들이 서로 동등하게 연관되어있다 가정
- Extended-Deep Knowledge Tracing
- 기존 DKT에서 추가 요소:
- 학생 사전 지식, 응답률, 응답 시간
- 문제 정보, 난이도, 스킬 계층도, 스킬 연관성
- 기존 DKT에서 추가 요소:
- DKT+
- 기존 DKT loss function에서 두개의 regularization term 추가
- 답안 입력 재구성 능력 향상
- 비슷한 skill을 사용하는 문제에 대한 불안정한 답안 예측 감소
- 기존 DKT loss function에서 두개의 regularization term 추가
- Deep KnowledgeTracing with Dynamic Student Classification (DKT-DSC)
- K-means를 사용해 학생들을 skill들에 대한 성과에 기반한 그룹으로 분류
- 성과가 바뀔때 동적으로 업데이트
2.2.2 Memory-Augmented Knowledge Tracing Models
DKT 모델에 external memory sturcuture을 추가한 모델
Key-Value Memory Network(KVMN)을 사용해 학생 지식 수준을 나타낸다.
- Key matrix: 스킬을 나타냄
- Value matrix: 각 스킬에 대한 학생 숙련도를 나타냄
모델
- Dynamic Key-Value Memory Network (DKVMN)
- Static한 key matrix와 dynamic한 value matrix를 사용
- Value matrix에서 문제 $q_t$에 대한 학생의 지식 수준 검색
- 문제 $q_t$에 대한 정확도를 검색된 지식 수준을 활용해 예측
- $q_t$를 품으로써 얻는 지식을 value matrix에 업데이트
- 한계점
- 과거 문제들의 풀면서 얻은 skill이 현재 문제를 풀면서 얻은 skill과 연관이 없을 수 있음
- Static한 key matrix와 dynamic한 value matrix를 사용
- Sequential Key-Value Memory Networks (SKVMN)
- DKVMN의 한계점을 해결하기 위해 변경된 LSTM Hop-LSTM을 사용
- 연속된 문제들간 sequential dependency를 포착할 수 있음
- 연관된 문제들에 대한 학생의 지식 수준만을 업데이트 할 수 있음
2.2.3 Attentive Knowledge Tracing Models
Transformer 구조와 attention 기법을 활용한 KT 모델
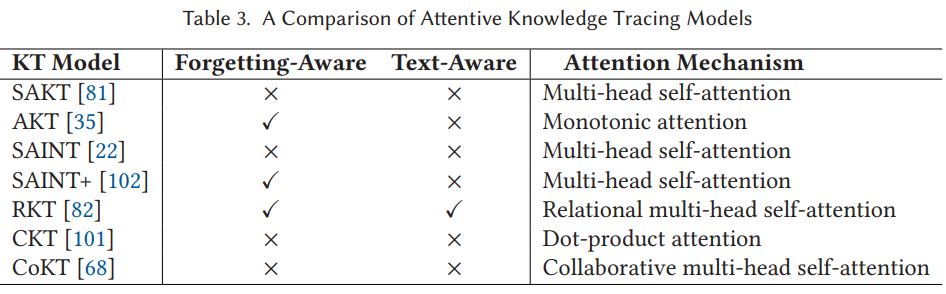
주요 아이디어
- 상호작용의 순차적인 문제들의 attention weight를 다음 주어진 문제를 정확히 예측하기 위한 확률을 나타내도록 학습
- DKT 알고리즘의 모든 순차적인 문제들에 동일한 중요도를 부여하는 한계를 극복
모델
- Self-Attentive Knowledge Tracing (SAKT)
- Attention 기법을 사용한 첫번째 논문
- 기존 Transformer 논문에서 제시된 scaled dot-product와 multi-head attention을 사용
- Attentive Knowledge Tracing (AKT)
- Monotonic attention 기법 사용
- 시간적 거리가 먼 문제의 attention weight를 exponential decay rate를 활용해 조절
- 시간에 따른 학생의 망각을 고려
- Rasch model을 활용해 각 문제가 각 개념의 지식 구성요소에서 얼마나 떨어져있는지 나타냄
- 시간적 거리가 먼 문제의 attention weight를 exponential decay rate를 활용해 조절
- Monotonic attention 기법 사용
- Separated Self-AttentIve Neural Knowledge Tracing (SAINT)
- Encoder-decoder 모델과 scaled dot-product attention 기법을 활용
- 학생의 순차적인 상호작용을 두가지로 분리
- Qeustion embedding sequence - encoder input으로 사용
- Response embedding sequence - decoder input으로 사용
- Encoder와 decoder는 기존 Transformer 구조와 동일
- 학생의 순차적인 상호작용을 두가지로 분리
- SAINT+
- Embedding sequence에 두가지 요소를 추가로 고려
- Elapsed time: 학생이 문제를 푸는데 걸린 시간
- Lag time: 두 연속된 학습 사이 시간
- Embedding sequence에 두가지 요소를 추가로 고려
- Encoder-decoder 모델과 scaled dot-product attention 기법을 활용
- RKT
- SAKT, SAINT와 비슷하게 기존 Transformer 구조를 사용
- Attention weight를 결합할 때 relation coefficients를 사용
- Relation coefficients는 다음 두가지 요소로 계산:
- Exercise relation modeling
- 문제의 text 정보를 활용해 과거 상호작용한 문제간 관계를 예측
- Foregetting behavior modeling
- 시간에 따라 망각하는 학생의 특성을 모델링
- Exercise relation modeling
- Relation coefficients는 다음 두가지 요소로 계산:
- CKT
- Attention을 1-D convolution network를 활용해 결합
- 학생 개개인의 skill을 다음 두가지로 나타냄:
- 연관성있는 과거 수행 능력
- 최신 문제와 각각의 이전 문제 사이 masked-attention을 사용
- 개념에 대한 전체적인 수행 능력
- 각 개념에서 맞춘 문제 비율 사용
- 연관성있는 과거 수행 능력
- Linear gating 기법을 통해 개별적인 feature를 결합하고 정답률을 예측
- 1-D convolution을 통해 최종 representation을 추출
- CoKT
- 추천 시스템의 collaborative filetering 아이디어 사용
- Intra-state (문제 풀이 기록)과 inter-state (동료 학생의 지식 수준)을 융합해 예측
- String-encoded 문제 풀이 기록을 BM25 함수를 활용해 동료 학생 간 유사도 점수를 계산
- 비슷한 동료 학생 간 inter-state를 나타내는 embedding vector를 multi-head self-attention 기법을 통해 project
- 학생의 과거 문제 풀이 기록도 비슷한 방법을 통해 embed
- 최종적으로 intra-state와 inter-state를 결합해 정답률 예측
2.2.4 Graph-Based Knowledge Tracing Models
KT 작업에는 다양한 관계 구조가 존재
- Skill 간 유사도, 의존도, 문제와 스킬 대응 관계 등
Graph Neural Network (GNN)을 사용해 이런 관계를 효과적으로 나타냄

모델
- Graph-based Knowledge Tracing (GKT)
- Node: Skill
- Edge: Skill 간 의존도
- KT 문제를 시계열 노드 수준 분류 (time series node-level classification) 문제로 바꾸어 message-passing GNN 기법으로 풀이
- 그래프 생성 기법 두가지:
- Statistics-based 접근
- Learning-based 접근
- Graph-based Interaction Knowledge Tracing (GIKT)
- 문제와 skill 사이 관계를 그래프로 나타내고 유의미한 embedding을 학습하는 방식
- GKT와 차이점
- GKT는 한 문제가 하나의 skill에 대응한다 가정
- GIKT는 하나의 skill이 하나 이상의 문제와 연관있다 가정
- GNN을 사용해 문제들과 skill들의 embedding을 축적
- 상호작용 sequence의 각 문제 embedding을 RNN 모델로 보내 최종 학생 정오답을 예측
- Structure-based Knowledge Tracing (SKT)
- Skill들 사이에 여러 관계를 포착하기 위해 디자인됨
- 유사 (similarity) 관계, 선수 (prerequisites) 관계
- GKT와 유사점 / 차이점
- 유사점
- 한 문제가 한 skill에 대응한다 가정
- 차이점
- skill 간 하나의 관계만 포착하는 GKT와 다르게 SKT는 여러 관계를 포착
- 그래프 데이터를 요약할 때 시간적, 공간적 영향을 고려
- 유사점
- 최종적으로 embedding들을 결합해 RNN 모델로 보내 학생 정오답을 예측
- Skill들 사이에 여러 관계를 포착하기 위해 디자인됨
- Pre-training Embeddings via Bipartite Graph (PEBG)
- 사전 학습된 exercise embedding을 활용해 KT 정확도를 높이는 기법 제시
- KT 작업에서 존재하는 relation들:
- Exercise-skill 관계, exercise 간 유사도, skill 유사도
- 모든 relation을 exercise embedding에 나타내기 위해 exercise 난이도와 함께 bipartite 그래프를 사용
2.2.5 Text-Aware Knowledge Tracing Models
이제까지의 모델들은 학생과 문제의 상호작용만을 고려한다.
Text-aware KT 모델들은 문제의 textual feature들을 사용해 KT 성능을 높이고자 한다.
모델
- Exercise-Enhanced Recurrent Neural Network (EERNN)
- Bi-directional LSTM을 활용해 각 문제의 텍스트에서 representation을 추출
- 추출된 representation을 이전에 답한 문제들의 representation과 결합해 또다른 LSTM 모델로 학생의 지식 수준 추적
- 두개의 변형된 모델이 존재:
- EERNNM
- Markov property가 성립한다 가정
- 가장 최신에 관측된 학생 지식 수준만 학생의 정오답률에 영향을 준다 가정
- Markov property가 성립한다 가정
- EERNNA
- 이전 모든 지식 수준이 모두 영향을 준다 가정
- Attention 기법을 통해 이전 수준도 모두 결합
- 이전 모든 지식 수준이 모두 영향을 준다 가정
- EERNNM
- 추가 발전된 모델: Masked language model (MLM)
- 문제 representation을 학습하기 위해 pre-training을 사용해 성능 향상
- Exercise-Aware Knowledge Tracing (EKT)
- EERNN 모델에 여러 skill 정보를 통합
- EERNN과 차이점
- 지식 수준을 나타내기 위해 vector가 아닌 matrix를 사용
- 일련의 상호작용으로 학생이 여러 skill을 숙달하는데 각 문제가 어느정도로 영향을 미치는지 memory network를 사용해 수량화
- EERNN과 차이점
- EERNN 모델에 여러 skill 정보를 통합
- Adaptable Knowledge Tracing (AdaptKT)
- 학습된 KT 모델을 다른 domain으로 옮기면서 성능을 유지시키는 방법 제시
- 서로 다른 두 도메인 문제들로 학습된 deep auto-encoder 구조를 활용해 문제 embedding을 학습
- KT 모델을 기존 도메인으로 학습시키면서 두 도메인의 지식 수준의 mean discrepancy가 최소화되도록 정량화
- Relation-Aware Self-Attention for Knowledge Tracing (RKT)
- Hierarchical Graph Knowledge Tracing (HGKT)
2.2.6 Forgetting-Aware Knowledge Tracing Models
학생의 지식 수준을 추정하는데 망각은 중요한 요소이다.
이런 망각의 영향을 고려한 모델들은 다음과 같다:
- Deep Knowledge Tracing (DKT) + Forgetting
- DKT에 forgetting feature를 더한 모델
- Forgetting features:
- 현재 시점까지 학생이 답한 같은 skill을 사용하는 문제 수
- 같은 skill을 사용하는 문제를 답하고 지난 시간
- Skill 상관 없이 가장 최근에 문제를 답하고 지난 시간
- Knowledge Proficiency Tracing (KPT)
- Probabilistic matrix factorization 모델
- 두가지 사전 정보에 의거:
- Question priors: 문제와 skill 사이에 관계를 나타내도록 전문가가 마킹한 Q-matrix
- Student priors: 시간에 따라 변하는 학생 지식 수준을 learning curve와 forgetting curve 이론을 사용해 포착
- Learning / forgetting 요소는 다음 두가지 요소에 의해 영향을 받는다 가정
- 더 많은 연습을 할수록 더 높은 지식 수준을 얻는다
- 시간이 더 많이 지날수록 지식을 망각한다
- Learning / forgetting 요소는 다음 두가지 요소에 의해 영향을 받는다 가정
- 예측 성능을 향상시킨 Exercise-correlated Knowledge Proficiency Tracing (EKPT)가 존재
- HawkesKT
- Skill 숙련도는 같은 skill을 다루는 이전 문제와 상호작용 뿐만 아니라 다른 skill을 다루는 문제에도 영향을 받는다 가정 (cross-effect)
- 다른 과거 상호작용에 의한 cross-effect는 서로 다른 스킬의 숙련 서로 다른 시간전 변화를 가진다 가정
- Deep Graph Memory Network (DGMN)
- Forgetting-aware KT와 그래프를 합친 모델
- Skill space에서의 망각 모델링이 목표
- Skill간 관계를 포착하기 위해 지식 수준 memory를 사용한 동적 그래프를 생성
- 일련의 상호작용이 주어지면 attention 기법을 통해 문제를 관련된 skill에 연결
- Forgetting feature를 계산
- 문제 embedding, skill graph embedding, forgetting feature를 gating 기법을 활용해 융합
- Gating 출력은 다음 문제를 맞출 활률을 예측하는데 사용
- Learning Process-consistent Knowledge Tracing (LPKT)
- 정답 예측을 하면서 학생의 learning gain 고려
- Learning gain 정의
- 마지막으로 답한 문제 이후 변화한 지식 수준과 문제를 답한 시간 간격을 embedding 으로 나타냄
- LPKT 모델은 3개의 sequential memory cell로 구성되어 있음:
- Learning progress gate: 가장 최근에 답한 문제의 embedding을 문제 tag를 고려해 project
- Forgetting gate: 최근 두 learning progress embedding을 받아 forgetting effect를 고려한 출력 project
- Prediction cell: 두 gate의 출력을 사용해 문제 정오답 확률을 예측
2.2.7 Discussion
Deep learning KT 모델의 주요한 요소들:
- Knowledge state
- 학생의 지식 수준을 하나의 skill 또는 여러 skill들을 통해 나타내짐
- Deep learning KT 모델의 주요한 트렌드는 복잡하게 얽힌 skill들에 의해 동적으로 변화하는 지식 수준을 나타내는 기법 개발
- Skill dependencies
- 각 문제는 하나 또는 그 이상의 skill과 연관되어 있다고 가정
- 사전 지식을 제공함
- Deep learning KT 모델들의 주요한 도전은 skill들 간 의존성을 파악하는 것
- 크게 두가지 방법 존재:
- Attention 기법을 사용해 문제와 필요한 skill 간 관계를 학습
- Graph-based 학습을 통해 skill 간 관계나 문제와 필요한 skill간 관계를 학습
- 크게 두가지 방법 존재:
- 각 문제는 하나 또는 그 이상의 skill과 연관되어 있다고 가정
- Feature augmentation
- 망각을 모델링한 feature와 문제 text를 모델링한 textual feature를 사용해 모델 성능을 향상
- 추가적인 요소를 모델링함으로써 모델 정확도 향상 가능
- 하지만 항상 추가적인 요소가 존재하는 것은 아님
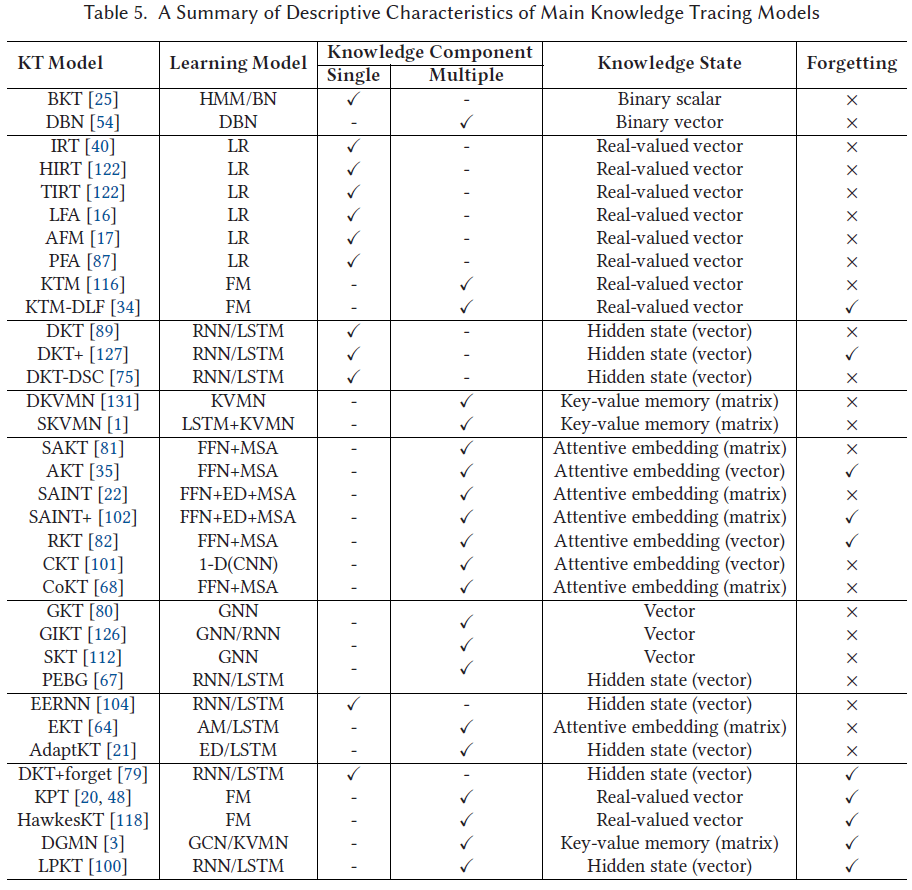
3 Knowledge Tracing Datasets
---


3.7 Considerations
Table 7은 binary classification 모델 성능을 보여준다.
- AUC는 KT 모델이 얼마나 정오답을 잘 구분하는지 보여줌
- 0 - 1: 0.5는 무작위 추측, 1은 완벽한 classifier를 나타냄
모델 성능 비교시 주의사항
- 실험 설정이 표준화되어있지 않기 때문에 직접적인 비교가 어려움
- 중복된 상호작용 데이터를 삭제하지 않았다면 더 좋은 결과가 나왔을 수 있음
- 각 데이터셋의 attribute에 대한 명시적인 설명이 없음
- 각 실험에서 서로 다르게 해석되었을 수 있음
- Noise 데이터나 잘못된 데이터의 정제 여부에 따라 성능 차이가 있을 수 있음
- Algebra 2006 - 2007에는 timestamp 오류가 있어 다른 두 Algebra 데이터 셋에 비해 성능이 낮음을 확인함
- 같은 데이터 셋을 썻음에도 불구하고 사용한 skill 수를 다르게 보고한 경우 다수 존재
- 데이터셋이 특정 과목, 특정 나라에서 생성되어 다양성이 부족함
- Benchmark 데이터셋은 수년에 걸쳐 업데이트 되기 때문에 특정 KT 모델들 실험에서 어느 버전을 썼는지 알 수 없음
4 Knowledge Tracing Applications
4.1 Educational Recommender Systems
- 목표
- KT 모델을 활용해 학생 지식 수준을 파악
- 지식 수준에 기반해 학습 자료를 추천
- 예시
- 그래프 기반 추천
- Predicting learners need for recommendation using dynamic graphbased knowledge tracing
- 학생들을 지식 수준에 기반해 그룹으로 분류하고 각 그룹에 가장 적절한 문제를 제공
- 강사가 특정 knowledge component (KC)를 선택
- 모델이 과거 기록에 기반해 동적 지식 그래프를 생성
- Node: 학생 지식 vector
- Edge: 선택된 KC 주변의 숙련 수준 유사도
- 그래프들은 node group으로 cluster 되고 각 그룹에 공유되는 embedding이 GNN을 사용해 만들어짐
- Embedding은 최종 문제 추천에 사용
- KT 모델로 계산된 보상 신호에 따라 문제를 추천하면 reinforcement learning recommender
- Learning path recommendation based on knowledge tracing model and reinforcement learning
- 교육 학습용 비디오 추천 모델
- Exploring multiobjective exercise recommendations in online education systems
- 그래프 기반 추천
---
5 Knowledge Tracing Future Research Directions
---
6 Conclusion
본 논문에서는 knowledge tracing에 대한 포괄적인 조사를 제공한다.