[논문] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
https://arxiv.org/abs/1502.03167
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Training Deep Neural Networks is complicated by the fact that the distribution of each layer's inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful param
arxiv.org
Deep Neural Networks를 학습시기키 어려운 이유 중 하나는 각 layer의 input distribution이 학습 과정에서 바뀌기 때문이다. 때문에 더 작은 learning rate와 조심스러운 parameter initialization을 필요로 하고 이는 모델 학습을 어렵게 만든다. 본 논문에서는 이 현상을 "internal convariate shift"라 부르고 layer input 정규화를 통해 이 문제를 해결한다.
1 Introduction
Stochastic gradient descent (SGD)는 deep network들을 학습시키는 효과적인 방법이다.
SGD는 parameter $\theta$를 loss를 최소화하는 방향으로 최적화시킨다:
$$\Theta = \arg\min_{\Theta} \frac{1}{N} \sum_{i=1}^{N} \ell(x_i, \Theta)$$
- $x_{1...N}$: Training data set
SGD에서는 학습이 step 단위로 진행되고 각 step에서는 사이즈 m의 mini-batch $x_{x...m}$를 사용한다.
이 mini-batch를 사용해 parameter에 대한 loss funtion의 기울기를 근사하게 된다:
- $\frac{1}{m} \frac{\partial \ell(x_i, \Theta)}{\partial \Theta}$
SGD는 신중한 hyper-parameter tunning을 필요로 한다. 특히 각 layer의 input은 이전 모든 layer들에게 영향을 받기 때문에 network parameter 변화의 영향은 모델이 깊어질수록 더 커지게 된다.
Layer의 input distribution 변화가 문제가 되는 이유는 layer가 계속해서 새로운 distribution에 적응해야 되기 때문이다.
- Learning system의 input distribution이 바뀌면 "covariate shift"를 경험한다고 지칭한다.
- 이 covariate shift는 learning system 전체가 아닌 각 구성요소들에게도 적용될 수 있다.
- 즉, 같은 input distribution을 가지면 학습에 더 효과적이다는 아이디어는 training data와 test data 뿐 아니라 각 sub-network를 학습시킬 때에도 동일하게 적용된다.
고정된 input distrubution을 가지는 것은 sub-network 밖에서도 긍정적인 효과를 만든다.
- 예를 들어 sigmoid 함수에서 input x의 절대값이 커질수록 0에 가까운 값을 가지게 된다.
- $z=g(Wu+b)$
- $g(x)=\frac{1}{1+exp(-x)}$
- 이는 절대값이 큰 x에 대해 u에게 적용되는 기울기가 모델에서 사라지게 만들고 학습을 느리게 만든다.
- 하지만 또 x는 W, b, 그리고 모든 아래에 있는 layer에 영향을 받는다. 따라서 학습 과정에서 x의 dimension들은 nonlinearity의 포화된 영역으로 움직이게 되고 convergence가 느려지게 된다.
위 문제들은 Rectified Linear Units와 careful initialization, 그리고 작은 learning rate로 해결될 수 있다.
하지만 nonlinearity input들이 같은 distribution을 가진다고 가정하면 더 효과적을 학습을 진행시킬 수 있다.
본 논문에서는 학습 과정에서 internal node들의 distribution이 바뀌는 것을 Internal Covariate Shift라 지칭한다.
본 논문에서는 이를 해결하는 새로운 기법인 Batch Normalization을 제시한다.
- 이는 각 layer input의 평균과 분산을 고정시켜 구현한다.
- 기울기가 parameter 크기와 초기값에 영향을 받지 않게 해주고 이는 높은 learning rate를 사용할 수 있게 해준다.
- 일반화 성능을 향상시키고 dropout을 사용하지 않게 해준다.
- 포화상태에서 network가 멈추는 현상을 없애기 때문에 saturating nonlinearities를 사용할 수 있게 해준다.
2 Towards Reducing Internal Covariate Shift
Whitening이 network의 빠른 수렴을 돕는다는 사실은 이미 잘 알려진 사실이다.
- 평균 0과 unit variance를 가지도록하거나 decorrelated 하게 만드는 것
따라서 각 layer의 input에 이런 whitening을 적용하면 internal covariate shift의 부정적인 영향을 없앨 수 있을 것이다.
먼저 각 training step 또는 약간의 간격을 두고 whitening을 진행해 보았다.
- 하지만 만약 이런 modification과 optimization step이 섞여 있으면 gradient descent step이 normalization이 업데이트되어야하는 방향으로 parameter들을 업데이트 할 수 있다.
- 이는 gradient descent optimization이 normalization이 적용된다는 사실을 고려하지 않기 때문에 생기는 문제이다.
이 문제를 해결하기 위해서 어떤 parameter 값에 대해서도 항상 원하는 distribution을 가지는 activation을 생성하도록 할 수 있다.
- $\hat{\mathbf{x}} = \text{Norm}(\mathbf{x}, \mathcal{X})$
- x: layer input
- $\mathcal{X}$: Training data set에 있는 input들
- 이는 parameter에 대한 loss의 기울기가 normalization과 model parameter의 의존성을 모두 고려하게 한다.
- 하지만 모든 layer input에 대해 whitening을 진행하는 것은 매우 비싼 작업이다.
- $\frac{\partial \text{Norm}(\mathbf{x}, \mathcal{X})}{\partial \mathbf{x}} \quad \text{and} \quad \frac{\partial \text{Norm}(\mathbf{x}, \mathcal{X})}{\partial \mathcal{X}}$
- Backpropagation 과정에서 위 두 Jacobians를 모두 계산해야 한다
따라서 본 논문에서는 미분 가능하고 모든 parameter 업데이트마다 training set 전체를 분석하지 않아도 되는 input normalization 기법을 탐구한다.
3 Normalization via Mini-Batch Statistics
각 layer input에 완전히 whitening을 진행하는 것은 비싸고 완전 미분 가능하지 않다. 따라서 두가지를 간략화 한다.
- 첫번째로 layer input과 output을 연결시켜 whitening을 진행시키는 대신 각 feature를 독립적으로 정규화시킨다.
- 평균은 0으로, 분산은 1로 고정
- d-차원 input $x=(x^{(1)}...x^{(d)})$을 가진 layer의 각 차원은 다음과 같이 정규화된다:
- $\hat{x}^{(k)} = \frac{x^{(k)} - \mathbb{E}[x^{(k)}]}{\sqrt{\operatorname{Var}[x^{(k)}]}}$
- Expectation과 variance는 training data set에서 계산된다
- Decorrelation 없이도 수렴을 빠르게 도와준다
- Input layer를 정규화시키면 layer가 나타낼 수 있는 표현에 영향을 줄 수 있다
- 이를 해결하기 위해 transformation이 identity transform을 나타내도록 한다:
- $y^{(k)} = \gamma^{(k)} \hat{x}^{(k)} + \beta^{(k)}$
- $\gamma^{(k)}$와 $\beta^{(k)}$는 모델 parameter와 함께 학습되어 모델의 표현력을 유지한다
- 두번째로 SGD에 mini-batch를 사용하기 때문에 각 mini-batch가 각 activation의 평균과 분산 근사치를 생성한다.
- 정규화에 사용된 통계 데이터를 backpropagation에 완전히 참여시킬 수 있다
- Mini-batch 사용은 joint covariance가 아닌 per-dimension varaince 계산을 하기 때문에 가능하다.
- 정규화에 사용된 통계 데이터를 backpropagation에 완전히 참여시킬 수 있다
크기 m의 mini-batch $\mathcal{B}$를 예시로 들자. 각 activation $x^{(k)}$에 정규화가 적용되기 때문에 k는 생략한다.
$$ \mathcal{B}=\{x_{1...m}\}$$
정규화 된 값들을 $\hat{x}$라 하고 그 값들의 linear transformation을 $y_{1...m}$이라 한다면:
$$\text{BN}{\gamma, \beta} : x{1 \dots m} \rightarrow y_{1 \dots m}$$
위 transform을 Batch Normalizing Transform이라 부른다.

하나 주의할 점은 BN transform은 각 training example을 독립적으로 process 하지 않는다.
- Training example과 mini-batch에 있는 다른 example 들에도 영향을 받는다 (위 두번째 간략화에 의함)
비록 transformation에 내재되어 있지만 정규화된 activation $\hat{x}$의 존재는 아주 중요하다.
- 각 정규화된 activation은 sub-network인 linear transformation $y^{(k)} = \gamma^{(k)} \hat{x}^{(k)} + \beta^{(k)}$ 를 거쳐 기존 네트워크의 process 과정을 거치게 된다
- 이 sub-network input이 정규화 되어 있기 때문에 학습 과정에서 sub-layer의 학습과 나아가 전체 network의 학습 속도를 빠르게 할 것이라 기대한다
또한 BN transform은 완전 미분가능하다:
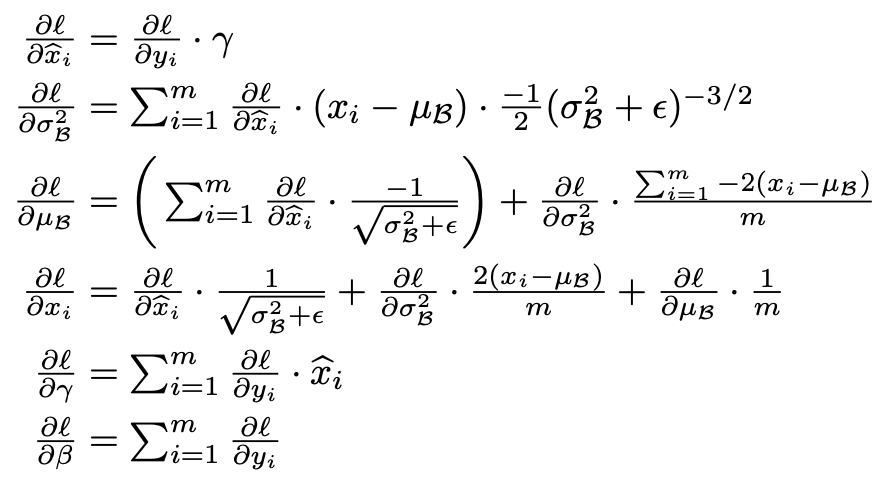
따라서 모델이 더 적은 covariate shift를 가지는 input distribution에 학습 가능하고 학습을 가속시킨다.
이런 normalized activation에 적용된 affine transform은 identity transformation을 나타내게 하고 network의 표현력을 유지시킨다.
3.1 Training and Inference with Batch Normalized Networks
Mini-batch에 의존하는 activation normalization은 효과적인 학습을 가능하게 한다.
하지만 inference 과정에서는 필요없을 뿐 아니라 바람직하지 않다.
Inference 과정에서는 output이 input에만 결정적이게 의존하기를 바란다. 따라서 network가 학습된 후 다음과 같은 정규화를 사용한다:
$$\hat{x} = \frac{x - \mathbb{E}[x]}{\sqrt{\operatorname{Var}[x] + \epsilon}}$$
- Mini-batch 통계가 아닌 전체 population 통계를 사용
Inference 과정에서는 unbiased variance estimate와 moving average를 사용한다.
- 따라서 평균과 분산은 고정된 값을 가지게 되고
- normalization은 $\gamma$와 $\beta$에 의한 간단한 linear transformation으로 대체되게 된다.

3.2 Batch-Normalized Convolutional Networks
Batch Normalization은 다양한 activation을 가지는 network에 적용될 수 있다.
아래 예제에서는 affine transformation 이후 element-wise nonlinearity를 가지는 transfrom을 보여준다.
$$z=g(Wu+b)$$
- W와 b: 학습된 parameter
- g: nonlinearity
BN을 두가지 위치에 넣을 수 있다
- 첫번째는 nonlinearity 바로 이전으로 $x=Wu+b$를 정규화한다
- Symmetric, non-sparse distribution을 가질 가능성이 높고 정규화가 안정적인 distribution을 가진 activation을 만들 가능성이 높다.
- 두번째는 u를 정규화하는 방법이다
- u는 또 다른 nonlinearity의 output이고 학습 과정에서 바뀔 가능성이 높다. 따라서 covariate shift를 없애기에 적당하지 않다.
따라서 BN은 nonlinearity 바로 이전에 적용한다. 또한 bias는 정규화 과정에서 무시될 수 있다:
$$z=g(BN(Wu))$$
- BN은 $x=Wu$의 각 차원에 독립적으로 적용되고 각 차원마다 $\gamma$와 $\beta$ 값을 학습한다.
Convolution layer에서는 추가적으로 convolutional property를 만족하기를 바란다:
- 같은 feature map에 있는 서로 다른 element들이 다른 위치에 있더라도 같은 방식으로 정규화되야 한다
이를 위해서 mini-batch 안에서 모든 위치의 activation들을 함께 정규화한다.
- Algorithm 1에서 mini-batch $\mathcal{B}$가 mini-batch의 element들과 모든 공간적 위치에 있는 feature map의 값들로 정의한다
- 따라서 mini-batch 크기 m과 feature map 크기 p x q에서 effective mini-batch 크기는 m*p*q이다
- 각 activation마다 $\gamma$와 $\beta$ 값을 학습하는게 아니라 각 feature map마다 학습한다.
- Algorithm 2도 마찬가지로 주어진 feature map의 각 activation에 같은 BN transform을 적용하도록 한다.

3.3 Batch Normalization enables higher learning rates
Activation을 정규화 시킴으로써 parameter의 작은 변화가 network를 거치면서 너무 크게 확대되는 것을 막는다.
또 BN은 학습이 parameter 크기에 더 회복력있게 만든다.
- 큰 learning rate는 layer parameter 크기를 증가시키고 이는 backpropagation 과정에서 기울기가 커져 모델이 터지게 만든다.
- 하지만 BN을 거치면 backpropagation이 parameter의 크기에 영향을 받지 않게 만들 수 있다.
- 예시로 scalar a에 대해
- $BN(Wu)=BN((aW)u)$
- $\frac{\partial \text{BN}((aW)\mathbf{u})}{\partial \mathbf{u}} = \frac{\partial \text{BN}(W\mathbf{u})}{\partial \mathbf{u}}$
- $\frac{\partial \text{BN}((aW)\mathbf{u})}{\partial (aW)} = \frac{1}{a} \cdot \frac{\partial \text{BN}(W\mathbf{u})}{\partial W}$
- Scale은 layer Jacobian과 gradient propagation에 영향을 주지 않는다
- 또한 큰 weight는 작은 gradient를 가지게 되고 parameter growth를 안정화한다
- 예시로 scalar a에 대해
3.4 Batch Normalization regularizes the model
BN을 사용하면 하나의 training example이 다른 traning example들과 연결되어 처리된다.
이는 정규화 효과를 가져온다.
4 Experiments
4.1 Activations over time
Internal covariate shift와 BN의 효과를 검증하기 위해 MNIST dataset을 이용한다.
Network 구조
- Input: 28x28 binary image
- 3 fully-connected hidden layer, 각각 100 activations
- 각 hidden layer는 sigmoid nonlinearity $y=g(Wu+b)$ 계산
- 각 weight W는 무작위 Gaussian 값들로 초기화
- 마지막 layer는 10개 activation의 fully-connected layer
학습은 50000 steps, mini-batch 당 60 example로 구성한다. 각 hidden layer에 BN을 적용한다.
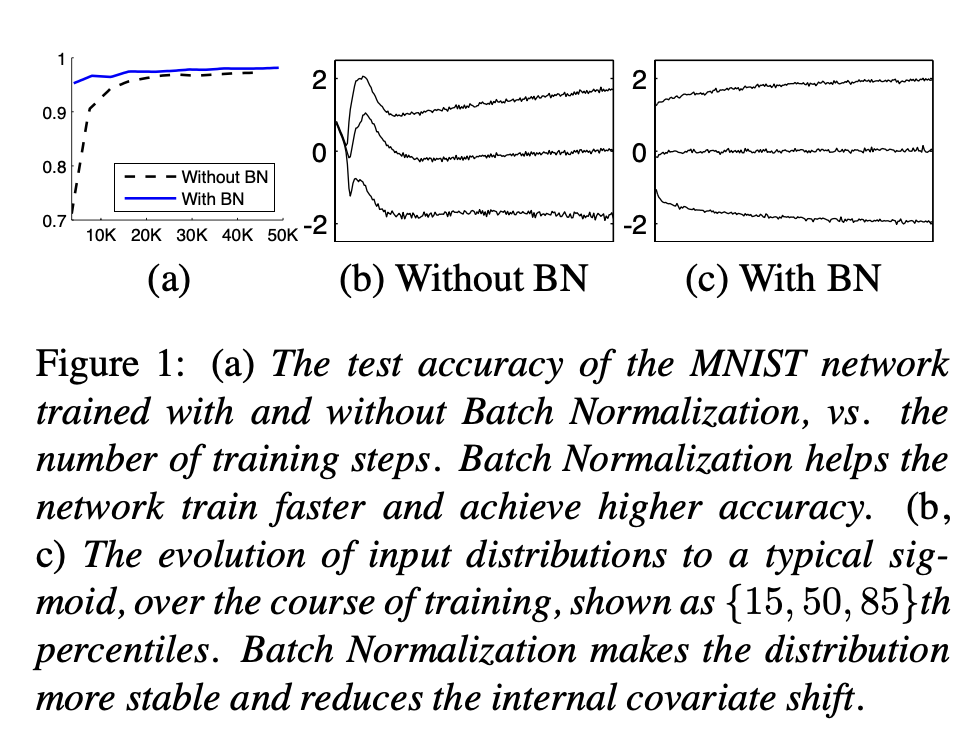
위 Figure 1 (a)에 따르면 학습 과정에서 BN network가 더 높은 test accuracy를 보여준다.
그 이유를 조사하기 위해 각 network의 sigmoid 함수에 들어가는 input을 비교한다:
- Figure (b, c)는 각 network의 마지막 hidden layer activation의 sigmoid input distribution이 어떻게 바뀌는지 보여준다.
- 기존 network의 distribution은 크게 바뀌는데 비해서
- BN network의 distribution은 크게 바뀌지 않는다.
4.2 ImagNet classification
BN을 Inception network의 새로운 변형에 적용한다.
Network 구조
- Nonlinearity: ReLU
- Inception network와 다르게 5x5 convolution layer들을 두개의 연속적인 3x3 convolution과 최대 128 filter로 교체
- 마지막 Fully-connected layer가 없음
모델 학습
- SGD
- Momentum은 사용하지 않음
- Mini-batch 32
모델 평가
- 학습 과정에서 held-out validation set으로 평가
- 이미지 당 하나의 crop 사용
BN은 각 nonlinearity의 input에 사용된다. (Convolutional way)
4.2.1 Accelerating BN Networks
단순히 BN을 추가하는 것은 제시된 기법을 완전히 이용하지 않는다.
추가로 다음과 같은 변경을 준다:
- Learning rate 증가
- 더 빠른 학습
- Dropout 제거
- L2 weight regularization 감소
- Learning rate decay 증가
- Local Response Normalization 제거
- Training example을 더 꼼꼼히 shuffle
- Mini-batch에 있는 example들이 다양할수록 BN에 더 좋은 영향
- Photometric distortion 감소
- 학습이 더 빠르게 되기 때문에 더 "real"한 이미지에 집중
4.2.2 Single-Network Classification
모든 network들은 LSVRC2012 데이터 셋을 활용했다.
- Inception
- 기존 Inception 모델
- 초기 learning rate 0.0015
- BN-Baseline
- Inception과 같지만 각 nonlinearity 전에 BN이 적용됨
- BN-x5
- 4.2.1에서 설명된 변화가 적용된 모델
- 초기 learning rate 0.0075
- BN-x30
- BN-x5와 같지만 초기 learning rate 0.045
- BN-x5-Sigmoid
- BN-x5와 같지만 nonlinearity로 ReLU 대신 sigmoid 사용
- 기존 Inception 모델은 sigmoid는 의미가 없는 결과르 만들어냄
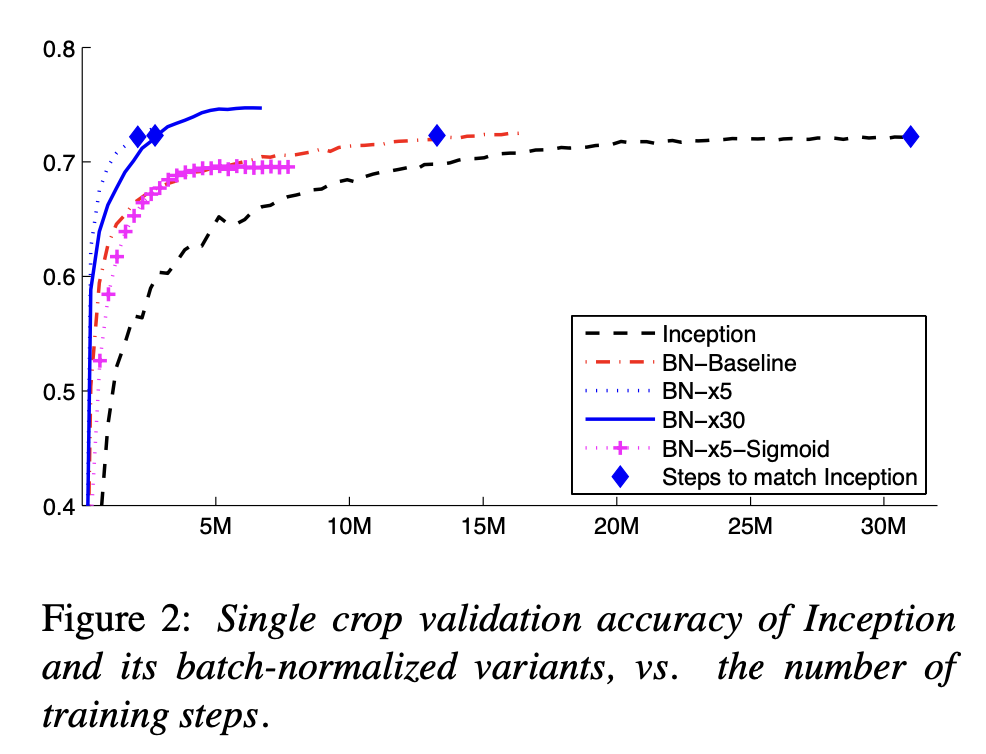

BN을 활용하여 기존 모델인 Inception의 최대 정확도를 절반보다 빠른 step에 도달한다.
또 4.2.1에 설명된 변경점을 사용한 BN-x5는 기존 모델보다 14배 빠른 수렴과 더 높은 정확도를 보여준다.
흥미로운 점은 더 높은 learning rate를 사용한 BN-x30에서는 가장 높은 정확도를 얻을 수 있었다.
또한 BN-x5-Sigmoid는 BN이 없을때 무작위 선택과 정확도가 똑같았는데 BN을 사용해 학습 가능함을 보여준다.
4.2.3 Ensemble Classification
BN-x30에 변경점을 추가해 6개의 network를 만들어 ensemble을 진행한다.
- Initial weight 증가
- Dropout 5%나 10% 적용
- Non-convolutional, per-activation BN을 마지막 layer에 적용
위 ensembel 기법들을 활용해 현존 모델들 중 가장 높은 성능을 얻었다.

5 Conclusion
본 논문에서는 deep networks들의 학습 속도를 매우 빠르게 해주는 기법을 제시한다. 이는 covariate shift를 줄이는 것을 기본으로 한다.
BN을 단순히 추가하는 것으로 학습 속도를 빠르게 하지 않는다. Learning rate나 dropout을 제거하는 등 여러 modification을 필요로 한다.