https://arxiv.org/abs/2306.06841
AI Tutor 시스템을 구축할 때 knowledge tracing은 중요한 역할을 합니다. 최근 problem solving history를 활용한 knowledge tracing 구현은 많은 발전을 이루었습니다. 하지만 문제 자체에 대한 지식 활용 기법은 많은 연구가 되지 않았습니다. 따라서 이 논문에서는 전문가가 라벨링한 skill-to-skill 관계를 활용한 knowledge-tracing 모델 구축 방법을 소개합니다.
Introduction
Knowledge tracing이란 학생의 미래 성과를 현재 knowledge로 판단하는 작업을 뜻한다
- 학생의 problem solving history 뿐만 아니라 problem metadata도 활용
Problem solving history를 활용한 모델은 꾸준히 연구되어 왔다. 하지만 문제 자체로도 많은 데이터를 얻을 수 있다.
- 예를 들어 문제 난이도, 문제 종류 (객관식, 주관식), 문제간 연관성 (skill-to-skill relationship)
Skill-to-skill relationship은 가장 중요하지만 잘 연구되지 않은 분야
- 특히 수학처럼 문제간 연관성이 핵심인 학문에서 중요
- 그래프의 형식으로 나타내지기 때문에 기존 knowledge tracing 모델에 쉽게 넣을 수 없음
본 논문에서는 전문가가 라벨링한 skill-to-skill information ASSIST2009-SSR를 사용한다
- 0과 1로 어떤 skill들이 연관되어 있는지 보여줌
- 5개의 서로 다른 관계 데이터로 구성됨
본 논문에서는 skill-to-skill 관계 데이터를 활용하는 knowledge tracing 기법을 소개한다
- Node2Vec 기법을 사용해 그래프 관계 데이터를 skill embeddeing data로 변환
- Projection-loss를 활용해 추가적인 skill-inherent 정보를 embedding data에 추가
제시된 기법으로 구현한 knowledge tracing 모델의 정량적 평과 결과 향상된 성능을 보여준다
- 특히 적은 데이터셋을 활용할 때 큰 성능 향상을 보임
Related work
Deep Knowledge Tracing (DKT)
- Algorithm based DKT이 RNN & LSTM based deep learning model로 발전
- BUT human knowlege를 통합하지 못함
DKT with knowledge graphs
- Graph neural network-based knowledge tracing 모델
- Pre-training the knowledge tracing with graph representation
본 논문에서 제시하는 모델은 이전 모델들에 비해 크게 세가지가 개선됐다
- Transformer layer로 유저의 문제 풀이 기록을 결합
- 전문가가 구축한 skill-to-skill relationship 데이터를 활용
- Human prior knowledge를 간단하고 효과적으로 결합
- Node2vec 기법으로 skill-to-skill relationship 데이터로부터 embedding 계산
- Projection layer-based optimization으로 knowledge와 knowledge tracing을 동시에 결합
Dataset
ASSIST09 dataset
대표적인 교육 benchmark 데이터셋
- 학생들이 능력을 개발할 수 있게 부여된 problem set
- 총 525,535개 기록을 제공
- 각 문제는 110개의 K-12 수학 커리큘럼에 필요한 스킬 중 하나 이상의 스킬에 태그됨

- 데이터셋에 많은 기록이 있음에도 불구하고 데이터셋의 sparsity 때문에 대부분의 interaction은 몇몇 소수 문제에 집중되어 있음
- 따라서 각 문제를 dense representation으로 나타내는데에는 한계가 있음
- 해결책으로 본 논문에서는 각 문제를 skill로 생각하고 그 skill을 의미있게 나타내는데에 집중함
Skill-to-skill relationships
- 4명의 수학 전문가를 선발해 ASSIST09에 있는 110개의 skill들 중 서로 연관 있다고 생각되는 skill pair를 라벨하도록 진행
- 더 정확한 라벨링을 위해 각 스킬을 5개의 카테고리 (algebra, probability, statistics, geometry) 중 1개로 분류
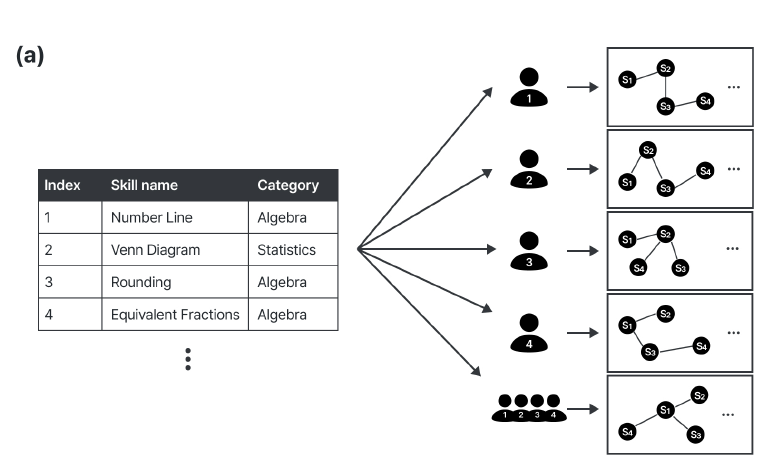
Methodology
Knowledge Tracing
Input: Probelm solving history
$$H = \left\{ (\pi_i, r_i) \right\}_{i=1}^{N_{\text{seq}}}$$
- $\pi_i$ :유저가 풀려는 문제
- $r_i \in \{0, 1\}$ : 유저가 올바른 정답을 적었는 지
- $ N_{\text{seq}} $ : Length of problem solving history
Input embedding:
$$k_j \text{ where } j \in [1, 2 \cdot N_{\text{skill}}]$$
- $j = \pi_i + r_i \cdot N_{\text{problem}}$
- $ k_j $ : 학생 상호작용 $(\pi_i, r_i)$를 관찰한 후 update on user knowledge
Problem embedding:
$$p_i \text{ where } i \in [1, N_{\text{problem}}]$$
- $ N_{\text{problem}} $ : Number of problems
Skill embedding:
$$s_i \text{ where } i \in [1, N_{\text{skill}}]$$
- $ N_{\text{skill}} $ : Number of skills
제시된 모델
Problem embedding sequences $ \{p_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $
+
Skill embedding sequnces $ \{s_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $
+
Input problem solving history $ \{\pi_i\}_{i=1}^{N_{\text{seq}}} $
=
학생이 정답을 제시할 확률 $\hat{r}_i$ 를 예측
Skill2Vec Input for Knowledge Tracing
Skill-to-skill relationships
- $G = (V, E)$ : Skill-to-skill graph
- $V = \{v_i\}, \, i \in [1, N_{\text{skill}}]$ : Skills
- $E = \{v_i, v_j\}, \, i, j \in [1, N_{\text{skill}}]$ : Skill 간 관계가 있는지
Graph를 vector로 변환하기 위해 Node2Vec를 사용
- 인접 노드의 likelihood를 최대화하기 위한 vector representation을 찾음
Problem-solving sequences에 있는 각 문제의 스킬들을 일련의 vector로 표현:
$$\{s_{\pi_i}\}_{i=1}^{N_{\text{seq}}}$$
본 논문에서는 이 vector를 Skill2Vec이라 지칭함

Skill Projection Loss
Skill2Vec을 단순히 input problem embedding에 추가하는 것은 두가지 문제점을 가짐
- 추가 vector에 따른 모호성 (의미 중복, 불확정성, 차원증가 노이즈 등등)
- Problem feature를 직접적으로 변경하면서 knowledge tracing의 주요 정보를 손상할 수 있음
따라서 본 논문에서는 skill projection loss를 제시
- Problem feature들이 skill-to-skill relation을 포함하면서도 기존 knowledge tracing 정보를 유지하도록 함
Skill projection loss:
- $ \{p_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $ : Problem embedding sequence
- $ \{p'_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $ : Projection layer를 거친 projected problem embedding sequence
- $ p'_i $ : i 번째 projected problem embedding
- $ s_i $ : i 번째 Skill2Vec feature
Deep Knowledge Tracing Model
Knowledge tracing에는 두가지 embedding sequence가 사용됨
- 문제에 대한 knowledge를 embed: $ \{p_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $
- 학생의 knowledge state를 업데이트할 때 embed: $ \{k_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $
본 논문에서는 knoledge tracing을 위해 Transformer 구조를 활용함
- Input source embedding: $ \{p_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $
- Input target embedding: $ \{k_{\pi_i}\}_{i=1}^{N_{\text{seq}}} $
Transformer의 output은 simple link layer를 통해 모델의 예측값 $ \hat{r}_i $를 생성
모델 예측값 $ \hat{r}_i $와 실제 학생의 정답여부 $ r_i $를 이용해 tracing loss $L_k$를 도출:
$$ L_k = -\frac{1}{N_{\text{seq}}} \sum_{i=1}^{N_{\text{seq}}} \left( r_i \log(\hat{r}_i) + (1 - r_i) \log(1 - \hat{r}_i) \right) $$
최종적으로 tracing loss와 skill projection loss를 사용해 최종 loss를 계산:
$$ L = L_k + \lambda L_p $$
- $\lambda$ : $L_k$와 $L_p$의 비율을 정하는 상수

Experiment
Experiment Details
Skill2vec
- Dimension: 25
Node2Vec
- Walk length: 128
- p: 1
- q: 1
- Number of walks: 300,000
- Window value: 4
Model
- Projection layer
- Simple, fully connected
- Hidden layer size: 100
- Transformer layer
- One head, four eoncoder layer, four decoder layer
- Dropout p: 0.05
- Optimizer: Adam optimizer
- Learning rate: 0.0002
Results

- Without Projection Loss: Projection loss를 고려하지 않은 모델 결과
- Random Skill-toSkill: 무작위 skill-to-skill 관계로 학습된 모델 결과
- Ours: 제시된 모델
두가지 결론을 얻을 수 있음
- 전문가가 라벨링한 skill to skill 관계가 knowledge tracing 성능에 유의미한 영향을 미침
- Skill-to-skill 관계의 quality가 중요함
Results on Limited Dataset
기존 데이터의 5%, 10%, 50%로 학습을 진행한 결과

적은 데이터셋으로 학습될수록 제시된 모델의 정확도 향상폭이 더 큰 것을 알 수 있음
Conclusion
본 논문에서는 skill-to-skill 관계를 활용한 knowledge tracing 기법을 소개한다.
실험 결과 real-world dataset에서 유의미한 AUC 향상 결과를 보여주었다.
이는 human domestic knowledge의 활용이 더 좋은 knowledge tracing 모델을 만들 수 있다는 것을 보여준다.


